การสำรองฐานข้อมูล SQL และอัพโหลดไปเก็บไว้บน Amazon S3 นั้นเป็นอีกวิธีหนึ่งในการสำรองข้อมูลบนเซิฟเวอร์ และอัพโหลดไปที่อื่น (Off-site Backup) ซึ่งเป็นหนึ่งในวิธีการสำรองข้อมูลที่ควรจะมีไว้เผื่อกรณีฉุกเฉิน โดยในที่นี้เป็นการเขียนสคริปต์บน Linux เพื่อทำงานดังนี้
- สั่งให้ระบบทำการ Dump ฐานข้อมูล
- อัพโหลดไฟล์ที่ Dump ออกมาไปยัง Amazon S3
Step 1: สร้าง IAM Account เพื่อใช้ในการอัพโหลด
ในการอัพโหลดข้อมูลขึ้นไปบน S3 นั้นจะต้องใช้ Access Key ซึ่งจะผูกกับ AWS Account โดยในที่นี้แนะนำให้สร้างแอคเคาท์ใหม่เพื่อใช้สำหรับอัพโหลดข้อมูล Backup โดยเฉพาะ
1. ใน AWS ไปยัง Service IAM และคลิก Add User
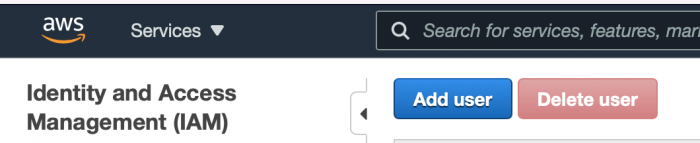
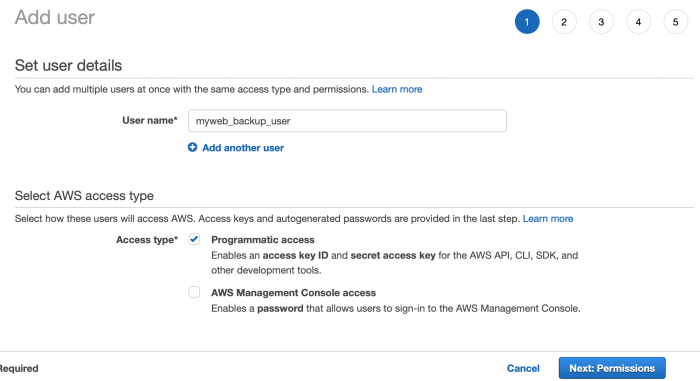
2. กรอกชื่อผู้ใช้งานที่ต้องการ และเลือกเปิดใช้งานเฉพาะ Programmatic access และคลิก Next ไปจนถึงหน้า Create user โดยไม่ต้องสร้าง Permission ใดๆ
3. เมื่อสร้าง User แล้ว ระบบจะแสดงชื่อ User และคีย์ได้แก่ Access key ID และ Secret access key ให้เก็บข้อมูลนี้ไว้
Step 2: เตรียม S3 Bucket เพื่อใช้เก็บข้อมูล Backup
ขั้นตอนนี้จะเป็นการสร้าง Bucket สำหรับเก็บข้อมูล Backup โดยแนะนำให้สร้างเป็น bucket ใหม่ออกมาต่างหากสำหรับสำรองข้อมูลในแต่ละโปรเจค
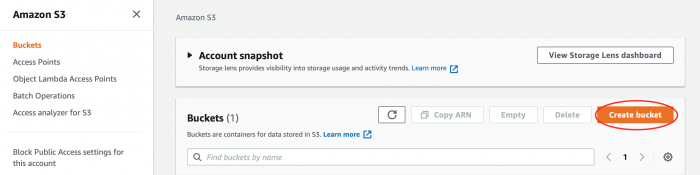
1. ลอคอินเข้าไปยัง AWS และไปยังเซอร์วิส S3 คลิกที่ Create Bucket
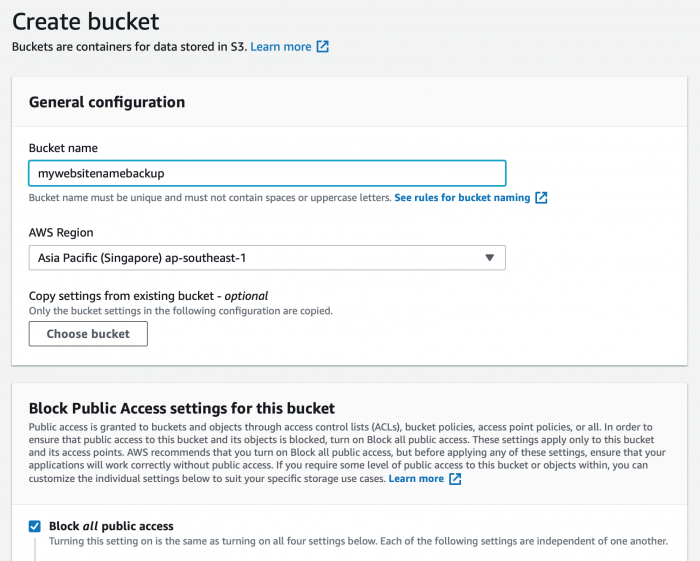
2. ตั้งชื่อ Bucket และตั้งค่าการเข้าถึงเป็น Block all public access แล้วคลิก Create Bucket
3. อนุญาตให้ IAM User ที่สร้างใน Step 1 สามารถเขียนข้อมูลลงใน S3 bucket ได้ โดยคลิกเข้าไปยัง Bucket ที่เพิ่งสร้างขึ้นใหม่ และไปที่แทป Permissions ด้านล่างจะมี Section ชื่อ Bucket Policy คลิก Edit
4. ตั้งค่า Policy ดังนี้
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::xxxxxxxx:user/xxxxxxx"
},
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::xxxxxxxx/*"
}
]
}AWS: เป็นข้อมูล ARN ของ User ที่สร้างใหม่ โดยสามารถดูได้จาก IAM > User คลิกเข้าไปยัง User ที่สร้าง จะปรากฎ ARN แสดงอยู่
Resource: เป็นชื่อของ Bucket ที่เพิ่งสร้างขึ้นมาเพื่อใช้ทำการ Backup
เมื่อตั้งค่าเรียบร้อยแล้วให้ Save Policy เป็นอันเสร็จสิ้นการสร้าง Bucket และ User
Step 3: ตรวจสอบหรือลง AWS CLI
ในการอัพโหลดข้อมูลไปยัง S3 นั้น เราจะใช้สคริปต์อย่างเป็นทางการของ AWS คือ AWS CLI โดยสามารถตรวจสอบได้ว่ามี AWS CLI ติดตั้งไว้แล้วหรือยังได้โดยใช้คำสั่ง
aws --version
# aws-cli/1.18.69 Python/3.8.10 Linux/5.4.0-1030-aws botocore/1.16.19หากยังไม่ได้ติดตั้งไว้ สามารถติดตั้งได้โดยใช้คำสั่ง
sudo snap install aws-cli --classicหรือลงโดยไม่ใช้ snap
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/installStep 4: เขียน Script ให้ dump ฐานข้อมูลที่ต้องการ และอัพโหลดไปยัง S3 bucket
1. สร้างไฟล์ชื่อ backup.sh สำหรับตั้งค่ารหัสผ่านฐานข้อมูล และคีย์ของ AWS
# ไปยังโฟลเดอร์ที่ต้องการเก็บสคริปต์
cd /home/ubuntu
vi backup.shตั้งค่าในไฟล์ ดังนี้
- AWS Access/Secret คือข้อมูลที่ได้จากการสร้าง User
- AWS Default Region ของ S3 Bucket
- MYSQL ข้อมูลชื่อผู้ใช้งาน รหัสผ่าน และชื่อฐานข้อมูลที่ต้องการ backup
- บรรทัดสุดท้ายจะเป็น path สำหรับไฟล์ที่จะทำการ Dump และอัพโหลดฐานข้อมูล ซึ่งจะสร้างขึ้นในขั้นต่อไป โดยให้เปลี่ยน path /home/ubuntu เป็นที่ๆเก็บไฟล์ดังกล่าว
#!/bin/bash
AWS_ACCESS_KEY_ID=xxxxxxxxxxxxxx \
AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxx \
AWS_DEFAULT_REGION=xxxxxxxxx \
S3_BUCKET=xxxxxxxxxxxxxx \
MYSQL_HOST=127.0.0.1 \
MYSQL_PORT=3306 \
MYSQL_USER=xxxxxxx \
MYSQL_PASS=xxxxxxx \
MYSQL_DB=xxxxxxx \
/home/ubuntu/dump_upload.sh*** กรณีฐานข้อมูลอยู่บน Docker ***
#!/bin/bash
AWS_ACCESS_KEY_ID=xxxxxxxxxxxxxx \
AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxx \
AWS_DEFAULT_REGION=xxxxxxxxx \
S3_BUCKET=xxxxxxxxxxxxxx \
DOCKER_NAME=xxxxxx \
MYSQL_USER=xxxxxxx \
MYSQL_PASS=xxxxxxx \
MYSQL_DB=xxxxxxx \
/home/ubuntu/dump_upload.sh2. สร้างไฟล์ชื่อ dump_upload.sh เป็นการสั่งให้ Dump ฐานข้อมูล และอัพโหลดไปยัง S3 โดยจะตั้งชื่อไฟล์เป็นวันที่ ซึ่งหากวันที่ซ้ำในเดือนถัดไป ข้อมูลจะถูกเขียนทับ จะทำให้ระบบเก็บข้อมูลแบ็คอัพไว้ไม่เกิน 1 เดือน
#!/bin/bash
cd /tmp
file=$(date +%d).sql
mysqldump \
--host ${MYSQL_HOST} \
--port ${MYSQL_PORT} \
-u ${MYSQL_USER} \
--password="${MYSQL_PASS}" \
${MYSQL_DB} > ${file} --no-tablespaces
if [ "${?}" -eq 0 ]; then
gzip ${file}
/usr/bin/aws s3 cp ${file}.gz s3://${S3_BUCKET}
rm ${file}.gz
else
echo "Error backing up mysql"
exit 255
fi*** กรณีฐานข้อมูลอยู่บน Docker ***
#!/bin/bash
cd /tmp
file=$(date +%d%m%y).sql
docker exec ${DOCKER_NAME} /usr/bin/mysqldump -u ${MYSQL_USER} --password="${MYSQL_PASS}" ${MYSQL_DB} > ${file} --no-tablespaces
if [ "${?}" -eq 0 ]; then
gzip ${file}
aws s3 cp ${file}.gz s3://${S3_BUCKET}
rm ${file}.gz
else
echo "Error backing up mysql"
exit 255
fi3. เมื่อสร้างทั้งสองไฟล์เรียบร้อยแล้ว เปลี่ยน Permission ให้สามารถ execute ไฟล์ได้โดยคำสั่ง
chmod +x dump_upload.sh
chmod +x backup.sh4. ทดสอบการแบ็คอัพโดยรันคำสั่ง
sh backup.shจากนั้นลองตรวจสอบดูในหน้าเว็บ AWS S3 ว่ามีไฟล์อัพโหลดขึ้นไปหรือไม่
หมายเหตุ หากมี Error หา aws cli ไม่เจอ:
ให้ใช้คำสั่ง เพื่อดูว่า path ของ aws cli อยู่ที่ใด
which aws
# /usr/bin/awsและให้นำค่านั้นๆไปแก้ไขที่ไฟล์ dump_upload.sh ในบรรทัดที่ 14
...
if [ "${?}" -eq 0 ]; then
gzip ${file}
aws s3 cp ${file}.gz s3://${S3_BUCKET} <----------
rm ${file}.gz
else
...Step 5: ตั้งค่า crontab เพื่อรันสคริปต์แบ็คอัพทุกวัน
เมื่อทำการตั้งค่าสคริปต์ backup เรียบร้อยหมดแล้ว จะต้องตั้งค่า crontab เพื่อให้ทำการรันสคริปต์ทุกวัน โดยใช้คำสั่ง
crontab -eจากนั้นเพิ่มบรรทัดเรียกสคริปต์ที่ล่างสุดของไฟล์ โดยจะตั้งให้เรียกใช้งานสคริปต์นี้ในเวลาเที่ยงคืนของทุกวัน
0 0 * * * /home/ubuntu/backup.shบันทึกข้อมูลและกลับออกมา สามารถทดสอบว่า crontab ได้ถูกบันทึกแล้วหรือยังได้โดยเรียกใช้คำสั่ง
crontab -lเท่านี้ฐานข้อมูลก็จะถูก dump และอัพโหลดขึ้นไปยัง S3 ทุกวันตามที่ตั้งค่าไว้ สามารถเปลี่ยนความถี่ในการแบ็คอัพได้โดยแก้ไขค่าใน crontab
โดยหากต้องการเปลี่ยนแปลงจำนวนการเก็บข้อมูล backup ก็สามารถเปลี่ยนแปลงชื่อไฟล์ที่ dump_upload.sh ในบรรทัดที่ 3 ได้ เช่น
# ชื่อไฟล์เป็นชั่วโมง 00-23 และวันที่ 01-31 เก็บข้อมูลรายชั่วโมง สุงสุด 31 วัน
# crontab สำหรับรันทุกชั่วโมง - 0 * * * * /home/ubuntu/backup.sh
file=$(date +%H-%d).sql
# ชื่อไฟล์เป็นวันที่ 01-31 เก็บข้อมูลสุงสุด 31 วัน
file=$(date +%d).sql
# ชื่อไฟล์เป็นวัน Mon-Sun เก็บข้อมูลสูงสุด 7 วัน
file=$(date +%a).sql
# ชื่อไฟล์เป็น m-d เก็บข้อมูลสูงสุด 1 ปี
file=$(date +%m-%d).sql
# ชื่อไฟล์เป็น Y-m-d เก็บข้อมูลทุกวัน ตลอดไป
file=$(date +%Y-%m-%d).sqlRestore
docker exec -i some-mysql sh -c 'exec mysql -u<user> -p<password> <database>' < /some/path/on/your/host/all-databases.sql